Introduction
The Video Decode and Presentation API for Unix (VDPAU) provides a complete solution for decoding, post-processing, compositing, and displaying compressed or uncompressed video streams. These video streams may be combined (composited) with bitmap content, to implement OSDs and other application user interfaces.
API Partitioning
VDPAU is split into two distinct modules:
The intent is that most VDPAU functionality exists and operates identically across all possible Windowing Systems. This functionality is the Core API.
However, a small amount of functionality must be included that is tightly coupled to the underlying Windowing System. This functionality is the Window System Integration Layer. Possibly examples include:
- Creation of the initial VDPAU VdpDevice handle, since this act requires intimate knowledge of the underlying Window System, such as specific display handle or driver identification.
- Conversion of VDPAU surfaces to/from underlying Window System surface types, e.g. to allow manipulation of VDPAU-generated surfaces via native Window System APIs.
Object Types
VDPAU is roughly object oriented; most functionality is exposed by creating an object (handle) of a certain class (type), then executing various functions against that handle. The set of object classes supported, and their purpose, is discussed below.
Device Type
A VdpDevice is the root object in VDPAU's object system. The Window System Integration Layer allows creation of a VdpDevice object handle, from which all other API entry points can be retrieved and invoked.
Surface Types
A surface stores pixel information. Various types of surfaces existing for different purposes:
- VdpVideoSurfaces store decompressed YCbCr video frames in an implementation-defined internal format.
- VdpOutputSurfaces store RGB 4:4:4 data. They are legal render targets for video post-processing and compositing operations.
- VdpBitmapSurfaces store RGB 4:4:4 data. These surfaces are designed to contain read-only bitmap data, to be used for OSD or application UI compositing.
Transfer Types
A data transfer object reads data from a surface (or surfaces), processes it, and writes the result to another surface. Various types of processing are possible:
- VdpDecoder objects process compressed video data, and generate decompressed images.
- VdpOutputSurfaces have their own rendering functionality.
- VdpVideoMixer objects perform video post-processing, de-interlacing, and compositing.
- VdpPresentationQueue is responsible for timestamp-based display of surfaces.
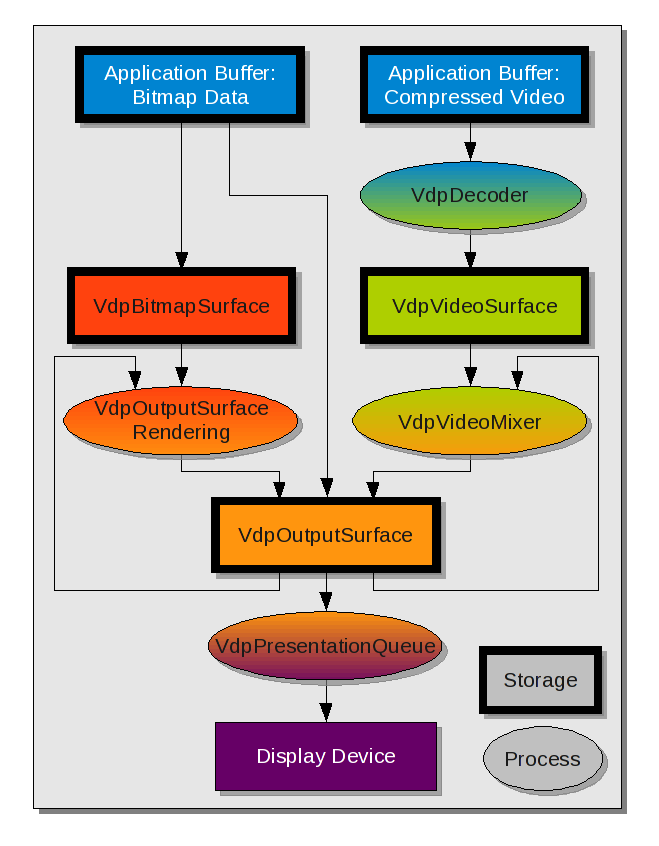
Data Flow
Compressed video data originates in the application's memory space. This memory is typically obtained using malloc, and filled via regular file or network read system calls. Alternatively, the application may mmap a file.
The compressed data is then processed using a VdpDecoder, which will decompress the field or frame, and write the result into a VdpVideoSurface. This action may require reading pixel data from some number of other VdpVideoSurface objects, depending on the type of compressed data and field/frame in question.
If the application wishes to display any form of OSD or user-interface, this must be created in a VdpOutputSurface.
This process begins with the creation of VdpBitmapSurface objects to contain the OSD/UI's static data, such as individual glyphs.
VdpOutputSurface rendering functionality may be used to composite together various VdpBitmapSurfaces and VdpOutputSurfaces, into another VdpOutputSurface "VdpOutputSurface".
Once video has been decoded, it must be post-processed. This involves various steps such as color space conversion, de-interlacing, and other video adjustments. This step is performed using an VdpVideoMixer object. This object can not only perform the aforementioned video post-processing, but also composite the video with a number of VdpOutputSurfaces, thus allowing complex user interfaces to be built. The final result is written into another VdpOutputSurface.
Note that at this point, the resultant VdpOutputSurface may be fed back through the above path, either using VdpOutputSurface rendering functionality, or as input to the VdpVideoMixer object.
Finally, the resultant VdpOutputSurface must be displayed on screen. This is the job of the VdpPresentationQueue object.
Entry Point Retrieval
VDPAU is designed so that multiple implementations can be used without application changes. For example, VDPAU could be hosted on X11, or via direct GPU access.
The key technology behind this is the use of function pointers and a "get proc address" style API for all entry points. Put another way, functions are not called directly via global symbols set up by the linker, but rather through pointers.
In practical terms, the Window System Integration Layer provides factory functions which not only create and return VdpDevice objects, but also a function pointer to a VdpGetProcAddress function, through which all entry point function pointers will be retrieved.
Philosophy
It is entirely possible to envisage a simpler scheme whereby such function pointers are hidden. That is, the application would link against a wrapper library that exposed "real" functions. The application would then call such functions directly, by symbol, like any other function. The wrapper library would handle loading the appropriate back-end, and implementing a similar "get proc address" scheme internally.
However, the above scheme does not work well in the context of separated Core API and Window System Integration Layer. In this scenario, one would require a separate wrapper library per Window System, since each Window System would have a different function name and prototype for the main factory function. If an application then wanted to be Window System agnostic (making final determination at run-time via some form of plugin), it may then need to link against two wrapper libraries, which would cause conflicts for all symbols other than the main factory function.
Another disadvantage of the wrapper library approach is the extra level of function call required; the wrapper library would internally implement the existing "get proc address" and "function pointer" style dispatch anyway. Exposing this directly to the application is slightly more efficient.
Multi-threading
All VDPAU functionality is fully thread-safe; any number of threads may call into any VDPAU functions at any time. VDPAU may not be called from signal-handlers.
Note, however, that this simply guarantees that internal VDPAU state will not be corrupted by thread usage, and that crashes and deadlocks will not occur. Completely arbitrary thread usage may not generate the results that an application desires. In particular, care must be taken when multiple threads are performing operations on the same VDPAU objects.
VDPAU implementations guarantee correct flow of surface content through the rendering pipeline, but only when function calls that read from or write to a surface return to the caller prior to any thread calling any other function(s) that read from or write to the surface. Invoking multiple reads from a surface in parallel is OK.
Note that this restriction is placed upon VDPAU function invocations, and specifically not upon any back-end hardware's physical rendering operations. VDPAU implementations are expected to internally synchronize such hardware operations.
In a single-threaded application, the above restriction comes naturally; each function call completes before it is possible to begin a new function call.
In a multi-threaded application, threads may need to be synchronized. For example, consider the situation where:
- Thread 1 is parsing compressed video data, passing them through a VdpDecoder object, and filling a ring-buffer of VdpVideoSurfaces
- Thread 2 is consuming those VdpVideoSurfaces, and using a VdpVideoMixer to process them and composite them with UI.
In this case, the threads must synchronize to ensure that thread 1's call to VdpDecoderRender has returned prior to thread 2's call(s) to VdpVideoMixerRender that use that specific surface. This could be achieved using the following pseudo-code:
Finally, note that VDPAU makes no guarantees regarding any level of parallelism in any given implementation. Put another way, use of multi-threading is not guaranteed to yield any performance gain, and in theory could even slightly reduce performance due to threading/synchronization overhead.
However, the intent of the threading requirements is to allow for e.g. video decoding and video mixer operations to proceed in parallel in hardware. Given a (presumably multi-threaded) application that kept each portion of the hardware busy, this would yield a performance increase.
Surface Endianness
When dealing with surface content, i.e. the input/output of Put/GetBits functions, applications must take care to access memory in the correct fashion, so as to avoid endianness issues.
By established convention in the 3D graphics world, RGBA data is defined to be an array of 32-bit pixels containing packed RGBA components, not as an array of bytes or interleaved RGBA components. VDPAU follows this convention. As such, applications are expected to access such surfaces as arrays of 32-bit components (i.e. using a 32-bit pointer), and not as interleaved arrays of 8-bit components (i.e. using an 8-bit pointer.) Deviation from this convention will lead to endianness issues, unless appropriate care is taken.
The same convention is followed for some packed YCbCr formats such as VDP_YCBCR_FORMAT_Y8U8V8A8; i.e. they are considered arrays of 32-bit pixels, and hence should be accessed as such.
For YCbCr formats with chroma decimation and/or planar formats, however, this convention is awkward. Therefore, formats such as VDP_YCBCR_FORMAT_NV12 are defined as arrays of (potentially interleaved) byte-sized components. Hence, applications should manipulate such data 8-bits at a time, using 8-bit pointers.
Note that one common usage for the input/output of Put/GetBits APIs is file I/O. Typical file I/O APIs treat all memory as a simple array of 8-bit values. This violates the rule requiring surface data to be accessed in its true native format. As such, applications may be required to solve endianness issues. Possible solutions include:
- Authoring static UI data files according to the endianness of the target execution platform.
- Conditionally byte-swapping Put/GetBits data buffers at run-time based on execution platform.
Note: Complete details regarding each surface format's precise pixel layout is included with the documentation of each surface type. For example, see VDP_RGBA_FORMAT_B8G8R8A8.
Video Decoder Usage
VDPAU is a slice-level API. Put another way, VDPAU implementations accept "slice" data from the bitstream, and perform all required processing of those slices (e.g VLD decoding, IDCT, motion compensation, in-loop deblocking, etc.).
The client application is responsible for:
- Extracting the slices from the bitstream (e.g. parsing/demultiplexing container formats, scanning the data to determine slice start positions and slice sizes).
- Parsing various bitstream headers/structures (e.g. sequence header, sequence parameter set, picture parameter set, entry point structures, etc.) Various fields from the parsed header structures needs to be provided to VDPAU alongside the slice bitstream in a "picture info" structure.
- Surface management (e.g. H.264 DPB processing, display re-ordering)
It is recommended that applications pass solely the slice data to VDPAU; specifically that any header data structures be excluded from the portion of the bitstream passed to VDPAU. VDPAU implementations must operate correctly if non-slice data is included, at least for formats employing start codes to delimit slice data. However, any extra data may need to be uploaded to hardware for parsing thus lowering performance, and/or, in the worst case, may even overflow internal buffers that are sized solely for slice data.
The exact data that should be passed to VDPAU is detailed below for each supported format:
MPEG-1 and MPEG-2
Include all slices beginning with start codes 0x00000101 through 0x000001AF. The slice start code must be included for all slices.
H.264
Include all NALs with nal_unit_type of 1 or 5 (coded slice of non-IDR/IDR picture respectively). The complete slice start code (including 0x000001 prefix) must be included for all slices, even when the prefix is not included in the bitstream.
Note that if desired:
- The slice start code prefix may be included in a separate bitstream buffer array entry to the actual slice data extracted from the bitstream.
- Multiple bitstream buffer array entries (e.g. one per slice) may point at the same physical data storage for the slice start code prefix.
VC-1 Simple and Main Profile
VC-1 simple/main profile bitstreams always consist of a single slice per picture, and do not use start codes to delimit pictures. Instead, the container format must indicate where each picture begins/ends.
As such, no slice start codes should be included in the data passed to VDPAU; simply pass in the exact data from the bitstream.
Header information contained in the bitstream should be parsed by the application and passed to VDPAU using the "picture info" data structure; this header information explicitly must not be included in the bitstream data passed to VDPAU for this encoding format.
VC-1 Advanced Profile
Include all slices beginning with start codes 0x0000010D (frame), 0x0000010C (field) or 0x0000010B (slice). The slice start code should be included in all cases.
Some VC-1 advanced profile streams do not contain slice start codes; again, the container format must indicate where picture data begins and ends. In this case, pictures are assumed to be progressive and to contain a single slice. It is highly recommended that applications detect this condition, and add the missing start codes to the bitstream passed to VDPAU. However, VDPAU implementations must allow bitstreams with missing start codes, and act as if a 0x0000010D (frame) start code had been present.
Note that pictures containing multiple slices, or interlace streams, must contain a complete set of slice start codes in the original bitstream; without them, it is not possible to correctly parse and decode the stream.
The bitstream passed to VDPAU should contain all original emulation prevention bytes present in the original bitstream; do not remove these from the bitstream.
MPEG-4 Part 2 and DivX
Include all slices beginning with start codes 0x000001B6. The slice start code must be included for all slices.
H.265/HEVC - High Efficiency Video Codec
Include all video coding layer (VCL) NAL units, with nal_unit_type values of 0 (TRAIL_N) through 31 (RSV_VCL31) inclusive. In addition to parsing and providing NAL units, an H.265/HEVC decoder application using VDPAU for decoding must parse certain values of the first slice segment header in a VCL NAL unit and provide it through VdpPictureInfoHEVC. Please see the documentation for VdpPictureInfoHEVC below for further details.
The complete slice start code (including the 0x000001 prefix) must be included for all slices, even when the prefix is not included in the bitstream.
Note that if desired:
- The slice start code prefix may be included in a separate bitstream buffer array entry to the actual slice data extracted from the bitstream.
- Multiple bitstream buffer array entries (e.g. one per slice) may point at the same physical data storage for the slice start code prefix.
Video Mixer Usage
VdpVideoSurface Content
Each VdpVideoSurface is expected to contain an entire frame's-worth of data, irrespective of whether an interlaced of progressive sequence is being decoded.
Depending on the exact encoding structure of the compressed video stream, the application may need to call VdpDecoderRender twice to fill a single VdpVideoSurface. When the stream contains an encoded progressive frame, or a "frame coded" interlaced field-pair, a single VdpDecoderRender call will fill the entire surface. When the stream contains separately encoded interlaced fields, two VdpDecoderRender calls will be required; one for the top field, and one for the bottom field.
Implementation note: When VdpDecoderRender renders an interlaced field, this operation must not disturb the content of the other field in the surface.
VdpVideoMixer Surface List
An video stream is logically composed of a sequence of fields. An example is shown below, in display order, assuming top field first:
t0 b0 t1 b1 t2 b2 t3 b3 t4 b4 t5 b5 t6 b6 t7 b7 t8 b8 t9 b9
The canonical usage is to call VdpVideoMixerRender once for decoded field, in display order, to yield one post-processed frame for display.
For each call to VdpVideoMixerRender, the field to be processed should be provided as the video_surface_current parameter.
To enable operation of advanced de-interlacing algorithms and/or post-processing algorithms, some past and/or future surfaces should be provided as context. These are provided in the video_surface_past and video_surface_future lists. In general, these lists may contain any number of surfaces. Specific implementations may have specific requirements determining the minimum required number of surfaces for optimal operation, and the maximum number of useful surfaces, beyond which surfaces are not used. It is recommended that in all cases other than plain bob/weave, at least 2 past and 1 future field be provided.
Note that it is entirely possible, in general, for any of the VdpVideoMixer post-processing steps other than de-interlacing to require access to multiple input fields/frames. For example, an motion-sensitive noise-reduction algorithm.
For example, when processing field t4, the VdpVideoMixerRender parameters may contain the following values, if the application chose to provide 3 fields of context for both the past and future:
current_picture_structure: VDP_VIDEO_MIXER_PICTURE_STRUCTURE_TOP_FIELD past: [b3, t3, b2] current: t4 future: [b4, t5, b5]
Note that for both the past/future lists, array index 0 represents the field temporally closest to current, in display order.
The VdpVideoMixerRender parameter current_picture_structure applies to video_surface_current. The picture structure for the other surfaces will be automatically derived from that for the current picture. The derivation algorithm is extremely simple; the concatenated list past/current/future is simply assumed to have an alternating top/bottom pattern throughout.
Continuing the example above, subsequent calls to VdpVideoMixerRender would provide the following sets of parameters:
current_picture_structure: VDP_VIDEO_MIXER_PICTURE_STRUCTURE_BOTTOM_FIELD past: [t4, b3, t3] current: b4 future: [t5, b5, t6]
then:
current_picture_structure: VDP_VIDEO_MIXER_PICTURE_STRUCTURE_TOP_FIELD past: [b4, t4, b3] current: t5 future: [b5, t6, b7]
In other words, the concatenated list of past/current/future frames simply forms a window that slides through the sequence of decoded fields.
It is syntactically legal for an application to choose not to provide a particular entry in the past or future lists. In this case, the "slot" in the surface list must be filled with the special value VDP_INVALID_HANDLE, to explicitly indicate that the picture is missing; do not simply shuffle other surfaces together to fill in the gap. Note that entries should only be omitted under special circumstances, such as failed decode due to bitstream error during picture header parsing, since missing entries will typically cause advanced de-interlacing algorithms to experience significantly degraded operation.
Specific examples for different de-interlacing types are presented below.
Weave De-interlacing
Weave de-interlacing is the act of interleaving the lines of two temporally adjacent fields to form a frame for display.
To disable de-interlacing for progressive streams, simply specify current_picture_structure as VDP_VIDEO_MIXER_PICTURE_STRUCTURE_FRAME; no de-interlacing will be applied.
Weave de-interlacing for interlaced streams is identical to disabling de-interlacing, as describe immediately above, because each VdpVideoSurface; Video Surface object already contains an entire frame's worth (i.e. two fields) of picture data.
Inverse telecine is disabled when using weave de-interlacing.
Weave de-interlacing produces one output frame for each input frame. The application should make one VdpVideoMixerRender call per pair of decoded fields, or per decoded frame.
Weave de-interlacing requires no entries in the past/future lists.
All implementations must support weave de-interlacing.
Bob De-interlacing
Bob de-interlacing is the act of vertically scaling a single field to the size of a single frame.
To achieve bob de-interlacing, simply provide a single field as video_surface_current, and set current_picture_structure appropriately, to indicate whether a top or bottom field was provided.
Inverse telecine is disabled when using bob de-interlacing.
Bob de-interlacing produces one output frame for each input field. The application should make one VdpVideoMixerRender call per decoded field.
Bob de-interlacing requires no entries in the past/future lists.
Bob de-interlacing is the default when no advanced method is requested and enabled. Advanced de-interlacing algorithms may fall back to bob e.g. when required past/future fields are missing.
All implementations must support bob de-interlacing.
Advanced De-interlacing
Operation of both temporal and temporal-spatial de-interlacing is identical; the only difference is the internal processing the algorithm performs in generating the output frame.
These algorithms use various advanced processing on the pixels of both the current and various past/future fields in order to determine how best to de-interlacing individual portions of the image.
Inverse telecine may be enabled when using advanced de-interlacing.
Advanced de-interlacing produces one output frame for each input field. The application should make one VdpVideoMixerRender call per decoded field.
Advanced de-interlacing requires entries in the past/future lists.
Availability of advanced de-interlacing algorithms is implementation dependent.
De-interlacing Rate
For all de-interlacing algorithms except weave, a choice may be made to call VdpVideoMixerRender for either each decoded field, or every second decoded field.
If VdpVideoMixerRender is called for every decoded field, the generated post-processed frame rate is equal to the decoded field rate. Put another way, the generated post-processed nominal field rate is equal to 2x the decoded field rate. This is standard practice.
If VdpVideoMixerRender is called for every second decoded field (say every top field), the generated post-processed frame rate is half to the decoded field rate. This mode of operation is thus referred to as "half-rate".
Implementations may choose whether to support half-rate de-interlacing or not. Regular full-rate de-interlacing should be supported by any supported advanced de-interlacing algorithm.
The descriptions of de-interlacing algorithms above assume that regular (not half-rate) operation is being performed, when detailing the number of VdpVideoMixerRender calls.
Recall that the concatenation of past/current/future surface lists simply forms a window into the stream of decoded fields. To achieve standard de-interlacing, the window is slid through the list of decoded fields one field at a time, and a call is made to VdpVideoMixerRender for each movement of the window. To achieve half-rate de-interlacing, the window is slid through the* list of decoded fields two fields at a time, and a call is made to VdpVideoMixerRender for each movement of the window.
Inverse Telecine
Assuming the implementation supports it, inverse telecine may be enabled alongside any advanced de-interlacing algorithm. Inverse telecine is never active for bob or weave.
Operation of VdpVideoMixerRender with inverse telecine active is identical to the basic operation mechanisms describe above in every way; all inverse telecine processing is performed internally to the VdpVideoMixer.
In particular, there is no provision way for VdpVideoMixerRender to indicate when identical input fields have been observed, and consequently identical output frames may have been produced.
De-interlacing (and inverse telecine) may be applied to streams that are marked as being progressive. This will allow detection of, and correct de-interlacing of, mixed interlace/progressive streams, bad edits, etc. To implement de-interlacing/inverse-telecine on progressive material, simply treat the stream of decoded frames as a stream of decoded fields, apply any telecine flags (see the next section), and then apply de-interlacing to those fields as described above.
Implementations are free to determine whether inverse telecine operates in conjunction with half-rate de-interlacing or not. It should always operate with regular de-interlacing, when advertized.
Telecine (Pull-Down) Flags
Some media delivery formats, e.g. DVD-Video, include flags that are intended to modify the decoded field sequence before display. This allows e.g. 24p content to be encoded at 48i, which saves space relative to a 60i encoded stream, but still displayed at 60i, to match target consumer display equipment.
If the inverse telecine option is not activated in the VdpVideoMixer, these flags should be ignored, and the decoded fields passed directly to VdpVideoMixerRender as detailed above.
However, to make full use of the inverse telecine feature, these flags should be applied to the field stream, yielding another field stream with some repeated fields, before passing the field stream to VdpVideoMixerRender. In this scenario, the sliding window mentioned in the descriptions above applies to the field stream after application of flags.
Extending the API
Enumerations and Other Constants
VDPAU defines a number of enumeration types.
When modifying VDPAU, existing enumeration constants must continue to exist (although they may be deprecated), and do so in the existing order.
The above discussion naturally applies to "manually" defined enumerations, using pre-processor macros, too.
Structures
In most case, VDPAU includes no provision for modifying existing structure definitions, although they may be deprecated.
New structures may be created, together with new API entry points or feature/attribute/parameter values, to expose new functionality.
A few structures are considered plausible candidates for future extension. Such structures include a version number as the first field, indicating the exact layout of the client-provided data. When changing such structures, the old structure must be preserved and a new structure created. This allows applications built against the old version of the structure to continue to interoperate. For example, to extend the VdpProcamp structure, define a new VdpProcamp1 and update VdpGenerateCSCMatrix to take the new structure as an argument. Document in a comment that the caller must fill the struct_version field with the value 1. VDPAU implementations should use the struct_version field to determine which version of the structure the application was built against. Note that you cannot simply increment the value of VDP_PROCAMP_VERSION because applications recompiled against a newer version of vdpau.h but that have not been updated to use the new structure must still report that they're using version 0.
Note that the layouts of VdpPictureInfo structures are defined by their corresponding VdpDecoderProfile numbers, so no struct_version field is needed for them. This layout includes the size of the structure, so new profiles that extend existing functionality may incorporate the old VdpPictureInfo as a substructure, but may not modify existing VdpPictureInfo structures.
Functions
Existing functions may not be modified, although they may be deprecated.
New functions may be added at will. Note the enumeration requirements when modifying the enumeration that defines the list of entry points.
Display Preemption
Please note that the display may be preempted away from VDPAU at any time. See Display Preemption for more details.
Trademarks
VDPAU is a trademark of NVIDIA Corporation. You may freely use the VDPAU trademark, as long as trademark ownership is attributed to NVIDIA Corporation.
